白云岛资源网 Design By www.pvray.com
<table><tr><td bgcolor=orange>本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删!</td></tr></table>
小鹅通 pri-cdn-tx.xiaoeknow.com开头的视频下载方法
环境
- win10
- Python3.9
方法一:手动抓包拼接下载地址
pri-cdn-tx.xiaoeknow.com开头的视频,m3u8文件中ts地址是加密的,没有办法直接提取出来替换
1.解析sign、us
def get_detail_info(self, resource_id): """ 提取视频原始下载地址和参数: 'param': '?sign=8c366cd81db547a00172a39d032444f0&t=63948ea8&us=bvZemXXVQx' """ headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Mobile Safari/537.36 Edg/105.0.1343.33', 'cookie': self.cookie } data = { 'bizData[resource_id]': resource_id, 'bizData[product_id]': self.product_id, 'bizData[opr_sys]': 'Win32' } response = requests.post(url, headers=headers, data=data) response = response.json() video_info = response['data']['video_info'] video_length = video_info['video_length'] file_name = video_info['file_name'] video_urls = response['data']['video_urls'] # m3u8 解密 video_urls = json.loads(self.dec_m3u8(video_urls)) results = [] for video_url in video_urls: host = video_url['ext']['host'] path = video_url['ext']['path'] baseuri = host + '/' + path + '/' param = '?' + video_url['ext']['param'] m3u8url = video_url['url'] # print(baseuri, param) info = { 'm3u8url': m3u8url, 'baseuri': baseuri, 'param': param, 'file_name': file_name } results.append(info) return results2.去视频播放页面抓包,随便抓一个ts链接
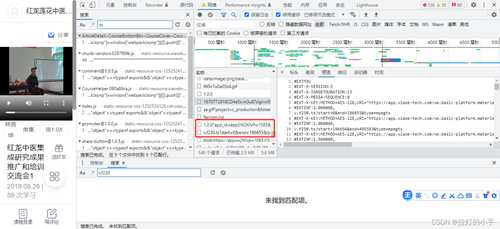
3.手动拼接完整m3u8地址
加密参数:
sign=1cedf0ef8927be6e5ac8fb12ec86d44e&t=63974ac0&us=tPzxDODjWL
ts地址:
https://encrypt-k-vod.xet.tech/2919df88vodtranscq1252524126/ab176def5285890794132337419/drm/v.f230.ts?start=0&end=196655&type=mpegts&sign=3f0b7ebfaa621ee2d9ac9dd5266b635c&t=63974e6c&us=VyiZZyhZvP
方法二:根据视频信息脚本自动导出下载地址
# 店铺IPAPPID = 'appsw2t0vpw1085'# 视频id# resource_id = 'v_637cc24ee4b0edc794f95a2a'# 专栏idproduct_id = 'p_5d8f2045bcc1d_i2P94QXd'# 登录cookieCOOKIE = 'ko_token=354b9d9b1708677a7ed5a5b7ff29754f'1.获取指定专栏下所有视频id
def get_h5_resource(self): """ 根据课程ID获取课程目录:H5页面 网页端 ko_token:随便抓个1.0或者2.0的包,提取token column_id:课程ID """ cookie = str(self.cookie).split('=')[1] headers = { "Host": "appav87zodt7514.h5.xiaoeknow.com", "sec-ch-ua": "\"Chromium\";v=\"106\", \"Google Chrome\";v=\"106\", \"Not;A=Brand\";v=\"99\"", "sec-ch-ua-mobile": "?0", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36", "retry": "1", "content-type": "application/x-www-form-urlencoded", "accept": "application/json, text/plain, */*", "req-uuid": "20221101114442000761199", "sec-ch-ua-platform": "\"Windows\"", "origin": "https://appav87zodt7514.h5.xiaoeknow.com", "sec-fetch-site": "same-origin", "sec-fetch-mode": "cors", "sec-fetch-dest": "empty", "accept-language": "zh-CN,zh;q=0.9" } data = { "bizData[column_id]": self.product_id, # 课程ID "bizData[page_index]": "1", "bizData[page_size]": "20", "bizData[sort]": "desc" } response = requests.post(url, headers=headers, cookies=cookies, data=data) total = response.json().get("data").get("total") print(f'共:{total} 节课程') data = response.json().get("data").get("list") resource_title = [i.get("resource_title") for i in data] resource_id = [i.get("resource_id") for i in data] for i in zip(resource_title, resource_id): print(i) yield i2.提取视频原始下载参数,及加密参数
def get_detail_info(self, resource_id): """ 提取视频原始下载地址和参数: 'param': '?sign=8c366cd81db547a00172a39d032444f0&t=63948ea8&us=bvZemXXVQx' """ headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Mobile Safari/537.36 Edg/105.0.1343.33', } data = { 'bizData[resource_id]': resource_id, 'bizData[product_id]': self.product_id, 'bizData[opr_sys]': 'Win32' } response = requests.post(url, headers=headers, data=data) response = response.json() video_info = response['data']['video_info'] video_length = video_info['video_length'] file_name = video_info['file_name'] video_urls = response['data']['video_urls'] # m3u8 解密 video_urls = json.loads(self.dec_m3u8(video_urls)) results = [] for video_url in video_urls: host = video_url['ext']['host'] path = video_url['ext']['path'] baseuri = host + '/' + path + '/' param = '?' + video_url['ext']['param'] m3u8url = video_url['url'] # print(baseuri, param) info = { 'm3u8url': m3u8url, 'baseuri': baseuri, 'param': param, 'file_name': file_name } results.append(info) return results3.提取ts加密文件并拼接下载地址
# 下载m3u8文件response = requests.get(m3u8url).text # 解key 不用key也能下载 # keyurl = re.findall('URI="(.+?)"',response)[0] + f'&uid={USERID}' # key = base64.b64encode(requests.get(keyurl).content).decode() # print(f'key: {key}') # 找到一个ts链接去生成m3u8链接 # 普通视频提取ts文件 # temp_url = re.findall('#EXTINF.+\n(.+?)_.+\?start=',response,re.DOTALL)[0] + '.m3u8' # https://pri-cdn-tx.xiaoeknow.com域名的视频提取ts文件:v.f230.m3u8 temp_url = re.findall(',+\n(.+?).ts\?start=', response, re.DOTALL | re.M | re.S)[0] + '.m3u8' print(temp_url) # 替换m3u8域名地址,构造下载m3u8视频下载地址 m3u8url = self.decrypt(baseuri + temp_url + param) print(file_name, m3u8url)效果
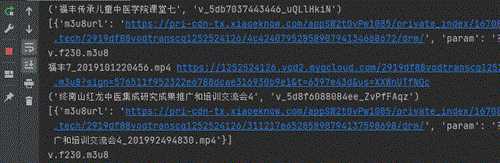
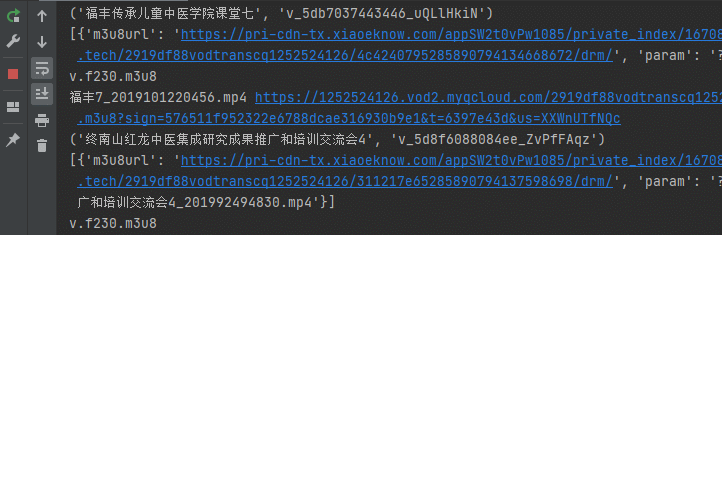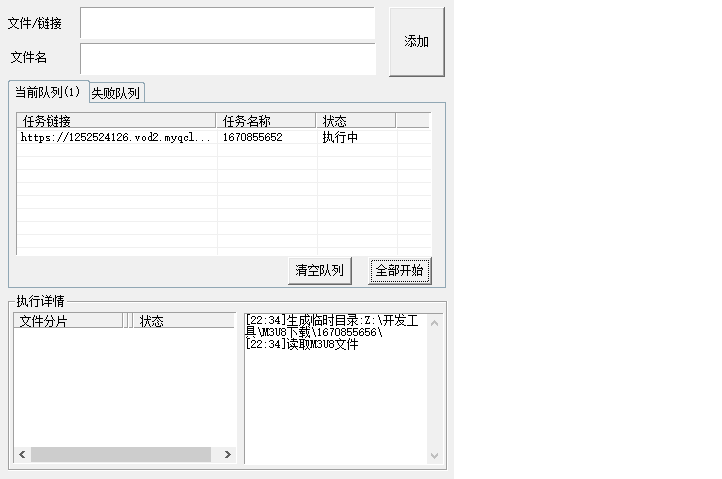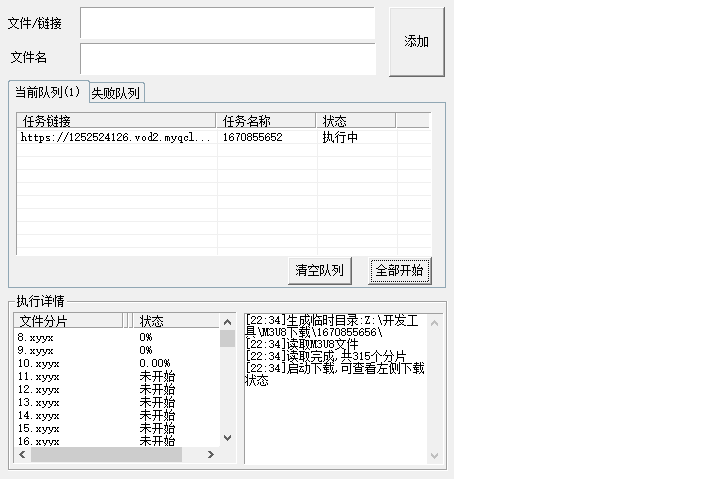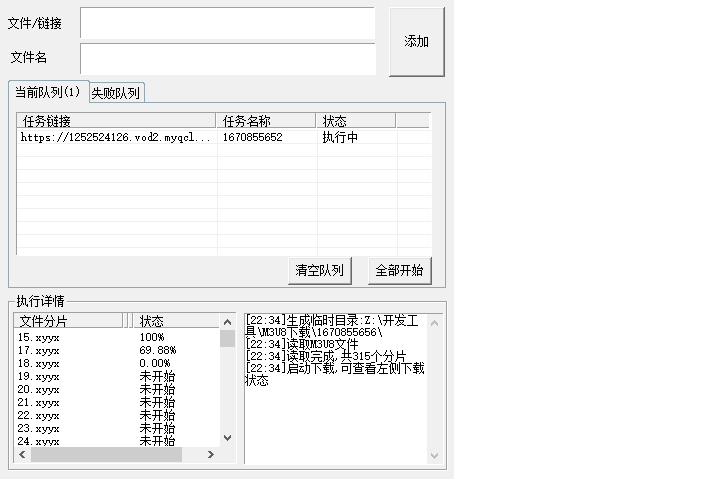
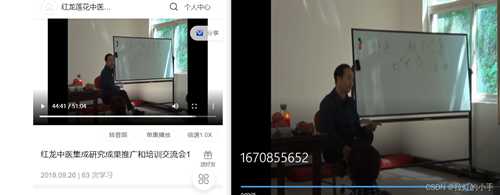
<table><tr><td bgcolor=orange>本文仅供学习交流使用,如侵立删!</td></tr></table>
白云岛资源网 Design By www.pvray.com