支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符
最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个。而且可能有几十份这样的试题。
而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档。这个如果是手动一个个粘贴到excel表格,那就头大了。
我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内容,大概就是问题、选项A、选项B等等。

但word文档是这种结构,如果按照网上通用的方式去转,基本上你得到的结果就是一大坨文字都在一格里,根本不符合需求。

最后我想到了一个解决思路,可以实现这个需求,先看看我转出来的结果:

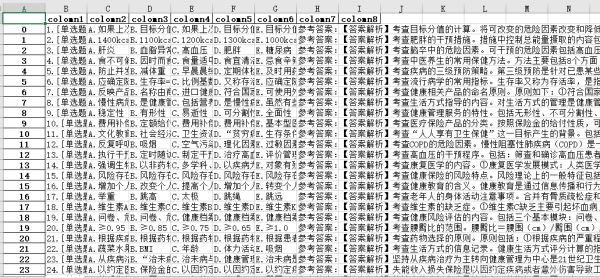
这个格式虽然跟最终的有点差别,但是只要在excel文档或者在代码里稍微再修改一下,就能完全符合要求了。
废话少说,先贴出代码,看得懂的可以直接拿去用,看不懂的,可以看我后面的具体说明。
已经把它封装成通用脚本了,你可以直接调用。
import pandas as pd
import os
# 初始处理函数1,先对初始处理结果进行判断
def initail_handle_by_range(file_path, max_page_num, split_str):
df = pd.read_table(file_path)
# 2、先转成Series
S = pd.Series(df['column1'].values)
# 3、转成列表,列表的每个元素就是每个段落
list = S.tolist()
# 传入一个max_page_num
# 4、遍历列表,取出每个段落,按“.”切割,取出第一个元素进行判断,如果它是题号,就应该得到"1"或者"10"
index_list = []
for content in list:
try:
# 不是每个段落都有“.”可以切割的,会报错,报错就跳过
first_str = content.split('%s'%split_str)[0]
# 5、根据最大的题号,自动生成匹配的字符串,用来匹配题号(每个匹配字符串都放在patch_list中)
patch_list = ['%d' % i for i in range(1, max_page_num + 1)]
# 6、比对切割得到的第一个元素,如果它在匹配的字符串中,就获取它在列表中的索引,并把获取到的结果添加到列表index_list中,这就知道了每道题的开头在l中的哪个位置了
if first_str in patch_list:
index = list.index(content)
index_list.append(index)
except:
pass
# 7、根据索引列表,我们可以知道每道题的第一段和最后一段在l中的哪个位置
# index_list = [0, 8, 16]
# print(index_list)
# 先计算每道题长度是否一致,不一致的,设置is_same_length = False
is_same_length = True
length = index_list[1] - index_list[0]
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 判断长度是否一致,不一致就对长度进行比较,把大的赋值给长度
if (end - start) != length:
is_same_length = False
if (end - start) > length:
length = (end - start)
result = [is_same_length, index_list, list, length]
return result
# 初始处理函数1,先对初始处理结果进行判断
def initail_handle_by_patchstr(file_path, patch_str, split_str):
df = pd.read_table(file_path)
# 2、先转成Series
S = pd.Series(df['column1'].values)
# 3、转成列表,列表的每个元素就是每个段落
list = S.tolist()
# 传入一个max_page_num
# 4、遍历列表,取出每个段落,按“.”切割,取出第一个元素进行判断,如果它是题号,就应该得到"1"或者"10"
index_list = []
for content in list:
try:
# 不是每个段落都有“.”可以切割的,会报错,报错就跳过
first_str = content.split('%s'%split_str)[0]
# 6、比对切割得到的第一个元素,如果它在匹配的字符串中,就获取它在列表中的索引,并把获取到的结果添加到列表index_list中,这就知道了每道题的开头在l中的哪个位置了
if first_str == patch_str:
index = list.index(content)
index_list.append(index)
except:
pass
# 7、根据索引列表,我们可以知道每道题的第一段和最后一段在l中的哪个位置
# index_list = [0, 8, 16]
# print(index_list)
# 先计算每道题长度是否一致,不一致的,设置is_same_length = False
is_same_length = True
length = index_list[1] - index_list[0]
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 判断长度是否一致,不一致就对长度进行比较,把大的赋值给长度
if (end - start) != length:
is_same_length = False
if (end - start) > length:
length = (end - start)
result = [is_same_length, index_list, list, length]
return result
# 传入一个文件路径和一个匹配的字符串,至少2个符号,例如"#."
def file_handle_by_patchstr(file_path, patch_str, split_str):
result = initail_handle_by_patchstr(file_path, patch_str, split_str)
# 接收初始处理函数的结果
is_same_length = result[0]
index_list = result[1]
list = result[2]
length = result[3]
# 先根据每道题的长度构造一个空的dict,最后用来生成dataFrame
dict = {}
for i in range(1, (length + 1)):
dict['colomn%d' % i] = []
# print(dict)
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 遍历一轮获得的结果就是我们要写入excel的一行
colomn = 1
for index in range(start, end):
# 遍历一次获得的结果就是我们要写入excel的一格
content = list[index]
# 每遍历一次就在一个dict中取出某一列,给它加上这个数据
dict['colomn%d' % colomn].append(content)
colomn += 1
# 在遍历到最后一轮的时候
if index == (end - 1):
# 判断是否需要插入空值
if not is_same_length and ((end - start) < length):
# 可能缺了2列,也可能缺了1列
content = ''
# 如果只是缺了一列,在现有的index上,加1,就是下一列,补上空值
if (length - (end - start)) == 1:
colomn = (end - start) + 1
dict['colomn%d' % (colomn)].append(content)
else:
# 如果缺失了2列以上,就遍历,给之后的每一列都补上空值
for i in range(length - (end - start)):
colomn = length - i
dict['colomn%d' % (colomn)].append(content)
final_df = pd.DataFrame(dict)
new_file_path = file_path.split('.')[0] + '.xlsx'
final_df.to_excel(r'%s' % new_file_path)
def file_handle_by_range(file_path, max_page_num, split_str):
result = initail_handle_by_range(file_path, max_page_num, split_str)
# 接收初始处理函数的结果
is_same_length = result[0]
index_list = result[1]
list = result[2]
length = result[3]
# 先根据每道题的长度构造一个空的dict,最后用来生成dataFrame
dict = {}
for i in range(1,(length+1)):
dict['colomn%d'%i] = []
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 遍历一轮获得的结果就是我们要写入excel的一行
colomn = 1
for index in range(start, end):
# 遍历一次获得的结果就是我们要写入excel的一格
content = list[index]
# 每遍历一次就在一个dict中取出某一列,给它加上这个数据
dict['colomn%d' % colomn].append(content)
colomn += 1
# 在遍历到最后一轮的时候
if index == (end - 1):
# 判断是否需要插入空值
if not is_same_length and ((end-start)<length):
# 可能缺了2列,也可能缺了1列
content = ''
# 如果只是缺了一列,在现有的index上,加1,就是下一列,补上空值
if (length-(end-start)) == 1:
colomn = (end-start) +1
dict['colomn%d'% (colomn)].append(content)
else:
# 如果缺失了2列以上,就遍历,给之后的每一列都补上空值
# 8-6 = 2, i = 0, 1
for i in range(length-(end-start)):
colomn = length - i
dict['colomn%d' % (colomn)].append(content)
final_df = pd.DataFrame(dict)
new_file_path = file_path.split('.')[0] + '.xlsx'
final_df.to_excel(r'%s'%new_file_path)
# 传入一个文件夹路径,最大的迭代数字,切割字符串
def dir_handle_by_range(dir_path, max_page_num, split_str):
files = os.listdir(dir_path) # 获取当前目录的所有文件及文件夹
for file in files:
file_path = os.path.join(dir_path, file) # 遍历获取每个文件的绝对路径
result = initail_handle_by_range(file_path, max_page_num, split_str)
# 接收初始处理函数的结果
is_same_length = result[0]
index_list = result[1]
list = result[2]
length = result[3]
# 先根据每道题的长度构造一个空的dict,最后用来生成dataFrame
dict = {}
for i in range(1, (length + 1)):
dict['colomn%d' % i] = []
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 遍历一轮获得的结果就是我们要写入excel的一行
colomn = 1
for index in range(start, end):
# 遍历一次获得的结果就是我们要写入excel的一格
content = list[index]
# 每遍历一次就在一个dict中取出某一列,给它加上这个数据
dict['colomn%d' % colomn].append(content)
colomn += 1
# 在遍历到最后一轮的时候
if index == (end - 1):
# 判断是否需要插入空值
if not is_same_length and ((end - start) < length):
# 可能缺了2列,也可能缺了1列
content = ''
# 如果只是缺了一列,在现有的index上,加1,就是下一列,补上空值
if (length - (end - start)) == 1:
colomn = (end - start) + 1
dict['colomn%d' % (colomn)].append(content)
else:
# 如果缺失了2列以上,就遍历,给之后的每一列都补上空值
for i in range(length - (end - start)):
colomn = length - i
dict['colomn%d' % (colomn)].append(content)
final_df = pd.DataFrame(dict)
new_file_path = file_path.split('.')[0] + '.xlsx'
final_df.to_excel(r'%s' % new_file_path)
# 传入一个文件夹路径和一个匹配的字符串,至少2个符号,例如"#."
def dir_handle_by_patchstr(dir_path, patch_str, split_str):
files = os.listdir(dir_path) # 获取目录的所有文件及文件夹
for file in files:
file_path = os.path.join(dir_path, file) # 遍历获取每个文件的绝对路径
print(file_path)
result = initail_handle_by_patchstr(file_path, patch_str, split_str)
# 接收初始处理函数的结果
is_same_length = result[0]
index_list = result[1]
list = result[2]
length = result[3]
# 先根据每道题的长度构造一个空的dict,最后用来生成dataFrame
dict = {}
for i in range(1, (length + 1)):
dict['colomn%d' % i] = []
# print(dict)
max_index = len(list)
for i in index_list:
# 如果i不是最后一个,那么start就是i,end就是i的下一个
if i < index_list[-1]:
start = i
end = index_list[index_list.index(i) + 1]
else:
start = i
end = max_index
# 遍历一轮获得的结果就是我们要写入excel的一行
colomn = 1
for index in range(start, end):
# 遍历一次获得的结果就是我们要写入excel的一格
content = list[index]
# 每遍历一次就在一个dict中取出某一列,给它加上这个数据
dict['colomn%d' % colomn].append(content)
colomn += 1
# 在遍历到最后一轮的时候
if index == (end - 1):
# 判断是否需要插入空值
if not is_same_length and ((end - start) < length):
# 可能缺了2列,也可能缺了1列
content = ''
# 如果只是缺了一列,在现有的index上,加1,就是下一列,补上空值
if (length - (end - start)) == 1:
colomn = (end - start) + 1
dict['colomn%d' % (colomn)].append(content)
else:
# 如果缺失了2列以上,就遍历,给之后的每一列都补上空值
for i in range(length - (end - start)):
colomn = length - i
dict['colomn%d' % (colomn)].append(content)
final_df = pd.DataFrame(dict)
print(final_df)
print(file_path)
new_file_path = file_path.split('.')[0] + '.xlsx'
print(new_file_path)
final_df.to_excel(r'%s' % new_file_path)
if __name__ == '__main__':
# 文件路径
# file_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\2018-04 技能操作真题.txt'
# 文件夹路径
dir_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\mytest'
# 根据数字处理具体文件,参数传文件路径,可迭代的最大数可自定义,分隔符也自定义
# file_handle_by_range(file_path, 100, '.')
# 根据自定义匹配符处理具体文件,参数传文件路径,匹配符可以自定义,切割符也可以自定义
# file_handle_by_patchstr(file_path, '#', '.')
# 根据数字处理具体整个文件夹,参数传文件路径,可迭代的最大数可自定义,分隔符也自定义
# dir_handle_by_range(dir_path, 100, '.')
# 根据自定义匹配符处理具体文件夹,参数传文件路径,匹配符可以自定义,切割符也可以自定义
# dir_handle_by_patchstr(dir_path, '#', '.')
一、先说一下实现这个需求的处理逻辑
解决这个需求的关键点是什么: 1、python怎么读取这个文件的内容? python有相关的word操作库可以读取,但是读取到的结果不方便操作。我们最终是要让它生成excel文件的,所以可以用python非常强大的科学计算包pandas来读取操作数据更好。
但pandas不能直接读取word文件,所以,需要先把它转成txt文档,这一步很简单,打开word,全部复制到一份新的txt文件中就行了。(注意要在第一行给它加上列名,我直接加了个colomn1,代表是第一列)简单处理后的txt文档的结构类似这样:

2、读取到的数据如何处理?
使用pandas读取到的数据是一个dataFrame,dataFrame的结构就类似于我们在excel文档里面那样行列分明的。但是,它从txt读取出来的格式是全部内容都视为1列的,而txt中的每一段,在它这里就是每一行(注意是每一段对应一行,而不是每一行对应每一行)预览一下:结果显示800行,1列。也就是在txt文档中有800个段落。

3、接下来怎么处理呢?
pandas强大的地方就在这里了,它可以直接把这1列的内容全部转成Series,Series是什么你可以不用管,你只需要知道Series可以直接转成列表list就行了。有了list我们就方便操作了。
以上几步就实现了从word里面读取数据,并转化成python的数据类型list了。list里面的每个元素,就等同于我们word里面的每一个段落。控制台打印出来的就是这样:下面的800是计算出这个列表的长度,代表有800个元素。

接下来我们的需求就变成了:怎么把一个列表,转成有明确行列结构的excel表格了。
这个要分为2种情况来说: 1、你的word文档结构相对合理些,每道题都固定是X个段落(例如每道题都是8个段落),这个解决就很简单了。因为这种情况对应就是在list中,每8个元素构成了1道题,你只要按照规律,8个8个取出,最后批量写入excel就行了。(这种解决起来比较简单,就不详细说了)
2、另一种情况比较麻烦,就是word文档的结构不规范,有的题目可能是8个段落,有的可能是7段,有的是6段。那么要怎么解决呢?
解决这个问题有几个关键点: 1、excel表格是行列结构的,它每一行的数据来源于这个txt文档的第几行?(也就是list里面的第几个元素)所以我们只要把每道题在list中的索引找出来就行了。
观察一下源数据,它每道题的开头都是数字加1个英文符号“.”,例如:“1.”和“2.”,最大的是"100.",并且其他段落的开头都不会出现这个结构。那么就简单了,我先构造出一个patch_list=[‘1', ‘2', ‘3'…‘100'],用来做匹配。
然后再遍历源数据列表,对列表的每个元素按“.”号切割,切割后拿到它的第一个元素,拿这个元素跟pacth_lis进行匹配,如果它是在patch_list中的,就代表它是每道题的开头。此时就记录下它的索引,并且把这个索引值存放到一个新列表index_list中。下面是我获取到的index_list:

0代表了第一道题是在列表的第1个元素开始的,8代表第二道题在列表的第9个元素开始。
于是我们就知道每道题的开头是在列表中的哪个位置了。
2、拿到了每道题的索引,然后怎么做呢?最终我们是要转存到excel文档中的, pandas怎么转excel?很简单的,只要你构造出一个dataFrame出来,调用pandas的to_excel方法,就能存入excel文档了。
3、问题的关键就变成了,有了每道题的索引,怎么把它转成dataFrame结构。下面演示一下,假如你想要构造一个dataFrame,需要什么样的数据结构,构造出来的dataFrame在控制台的输出结果是怎么样的,最后生成的excel表格是怎么样的。
dict = {'colomn1': ['问题1', '问题2', '问题3'],
'colomn2': ["A:问题1的A选项", "A:问题2的A选项", "A:问题3的A选项"],
'colomn3': ['B:问题1的B选项', 'B:问题2的B选项', 'B:问题3的B选项']}
df = pd.DataFrame(dict)
print(df)
df.to_excel(r'C:\Users\Administrator\PycharmProjects\exchange_file\test.xlsx')
这个就是调用pandas的DataFrame方法,用字典dict生成的一个dataFrame数据。这个dataFrame在控制台打印出来就是:

这个结构存入excel就是对应表格的行和列了。这个结构就符合我的实际需求了。

所以我们要构造出这个dataframe的关键就是:把所有数据梳理一遍,构造成类似这样的一个字典:
dict = {'colomn1': ['问题1', '问题2', '问题3'],
'colomn2': ["A:问题1的A选项", "A:问题2的A选项", "A:问题3的A选项"],
'colomn3': ['B:问题1的B选项', 'B:问题2的B选项', 'B:问题3的B选项']}
那么怎么构建这个dict呢?
我们源数据转出来的list结构是类似这样的: list = [‘问题1',“A:问题1的A选项”, ‘B:问题1的B选项'…‘问题2',“A:问题2的A选项”, ‘B:问题2的B选项']
而我们前面得到的index_list=[0, 8, 16。。。。] 它记录了“问题1”,“问题2”等等直到“问题100”是在哪个位置开始的,所以我们只需要把index_list遍历一下,轮流取出它的每个元素,它就是每道题的开始位置,然后拿到紧跟在这个元素的下一个是什么,用这个减去1就知道了每道题的开始位置start和结尾位置end是多少了。
接着使用
for i in range(start, end): content = list[i]
就可以轮番从list中取出每道题的各项内容,取到的第一个就加到dict的colomn1列表中,第二个就加到dict的colomn2中,按照这个规律,就能把list的内容分开插入到dict中的各个列表中了。
但在这个过程中,可能你每道题的段落数目不一致,也就是你按照这个规律从list中取出的元素,可能每次取出的数量都不一样。这点需要注意,如果没有对它进行处理,最后会导致转出来的文件内容错位了,例如你的文档里面,第一题有8个段落,第二题只有7个,第三题有8个段落,没处理这个问题的话,最后第三题的第8个段落,就会跑到第7题那边了。并且最终dataFrame会无法生成excel文件。
那么这个问题怎么解决呢?
在正式调用处理函数生成excel文件之前,可以先对文件预处理,拿到它们的数据进行判断,如果判断到它每个间隔不一样,有的缺少段落,那么就让数据预处理函数返回一个值为False,间隔一样就返回True。接着在真正的数据提取环节,根据这个进行判断,如果判断到它值是Fales,那么就在每一轮遍历提取数据的最后一次遍历,一次性在它后面的缺失数据的列加上空字符串,作为占位用,这样最后得到的列表长度就都一样了,并且在最后生成的excel表中,它是一个空格。
最后用dict生成dataFrame,再写入excel文档,我们就大功告成了。
二、再说一下具体怎么使用:
一、运行必须的工具 1、python解释器(pycharm或其他); 2、python自带模块:os; 3、自行安装模块:pandas,openpyxl;
自行安装的模块,在控制台pip install pandas和pip install openpyxl就行了。
二、怎么调用:
1、先要做数据预处理:先要把word文档的内容复制到txt文档中,并且在第一行加上"column1",处理后像下面这样:

接着要看你的文档内容是否有题号,如果有的话:比如像我这个,有具体的题号1-100题,并且它的写法都是“1.”,在题号后面跟了个英文字符'.‘,顺序递增到100。

那么你就可以调用file_handle_by_range。
你给它传第一个参数是个具体的文件路径,它就会去打开这个文件,读取里面的内容。
传的第二个参数是100,它就会自动生成1到100的字符串,用来匹配识别你的每道题的开头在哪个位置。(如果你最大的题号是200,就写200,可以写多,但不能写少,少了识别到的内容会缺失)
传的第三个参数是'.‘,它就会按照'.'去切割每一行的内容,拿到第一个“.”号前面的内容,用来跟它生成的匹配字符做比对,比对成功了,它就默认该行是你想要写到excel表格里的第一列,接在它后面的每个段落,会自动插入到它后面的列。
直到匹配到下一个“数字.”开头的,又重复这个过程。
如果你的文档里面并不是像我这样,没有顺序递增的题号,你可以手动给每个你想要放在表格中第一列的段落,在它前面加标识符,例如“####.”,注意最后是有个小点的。像下面这样:

接着调用
for i in range(start, end): content = list[i]
那么它就默认按照'.‘去切割每行内容,并且按照####来匹配识别切到的内容,如果切到在'.'前面的是“####”,那么它就默认这一段是你想存到excel表第一列的段落,在它后面的几段,都会按照每个段落存入一格去处理。直到下一个“####.”出现。
2、可调用的有4个函数: 2.1、假如你只想处理一个具体的文档,并且它有具体的题号,最大题号是100,并且它后面跟的是一个'.',那么就按照下面这个调用
file_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\2018-04 技能操作真题.txt' file_handle_by_range(file_path, 100, '.')
2.2、根据自定义匹配符处理具体文件,参数传文件路径,匹配符可以自定义,切割符也可以自定义
file_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\2018-04 技能操作真题.txt' file_handle_by_patchstr(file_path, '#', '.')
2.3、根据数字处理具体整个文件夹,参数传文件路径,可迭代的最大数可自定义,分隔符也自定义。(注意文件夹路径,最后是不跟文件名的,它是个文件夹,不是具体文件路径)
# 文件夹路径 dir_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\mytest' dir_handle_by_range(dir_path, 100, '.')
2.4、根据自定义匹配符处理具体文件夹,参数传文件路径,匹配符可以自定义,切割符也可以自定义
# 文件夹路径 dir_path = r'C:\Users\Administrator\PycharmProjects\exchange_file\mytest' dir_handle_by_patchstr(dir_path, '#', '.')
总结
以上所述是小编给大家介绍的python实现word文档批量转成自定义格式的excel文档的思路及实例代码,希望对大家有所帮助,也非常感谢大家对网站的支持!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。